- Published on
Multithreads and Multithreading Synchronization
- Authors

- Name
- Yue Zhang
- 1. Multithreading
- 2. Multithreading Synchronization
1. Multithreading
1.1 Concept of Threads
Over a decade ago, the mainstream opinion advocated for prioritizing multiprocessing over multithreading whenever feasible. However, multithreading has now become the standard practice in programming. Multithreading technology has significantly improved program performance and responsiveness, enabling more efficient use of system resources.
what is a thread? A thread is an execution context that contains various state data, including:
- Its own execution flow.
- Call stack.
- Error codes.
- Signal masks.
- Private data.
1.1.1 instruction/execution flow
In a task, instructions executed sequentially form an instruction sequence (a history of the Instruction Pointer register values). This sequence is referred to as an instruction flow or execution flow, and each thread has its own unique flow. Consider the following code example (written in C++):
int calc(int a, int b, char op) {
int c = 0;
if (op == '+')
c = a + b;
else if (op == '-')
c = a - b;
else if (op == '*')
c = a * b;
else if (op == '/')
c = a / b;
else
printf("invalid operation\n");
return c;
}
The calc function is compiled into assembly instructions, where each line of C code corresponds to one or more assembly instructions. When the calc function is executed in a thread, these machine instructions are executed sequentially.
However, the sequence of executed instructions may not exactly match the order in the source code. This discrepancy can arise due to:
- Branches and jumps in the logic, which alter the flow of execution.
- Compiler optimizations, such as instruction reordering, to improve efficiency.
- Processor out-of-order execution, which dynamically rearranges instructions to maximize hardware resource utilization.
These factors can influence the actual order of instruction execution, leading to a sequence that differs from the original code's apparent flow.
1.1.2 Logical Threads vs Hardware Threads
Logical threads
Logical threads, also referred to as tasks, soft threads, or logical threads, are conceptual constructs in software. Their execution logic is defined by the code. For example, a function to calculate the sum of elements in an integer array represents the logic of a thread:
void sumArray(int* arr, int size) {
int sum = 0;
for (int i = 0; i < size; ++i) {
sum += arr[i];
}
printf("Sum: %d\n", sum);
}
This function has simple logic and does not call any other functions (more complex logic can involve calling other functions within the function). We can call this function within a thread to calculate the sum of an array. Alternatively, we can set the sum function as the entry point for a thread, as each thread has an entry function from which its execution begins. For example:
void sumArray(int* arr, int size) {
int sum = 0;
for (int i = 0; i < size; ++i) {
sum += arr[i];
}
printf("Sum: %d\n", sum);
}
// A thread can execute sumArray as its entry point
std::thread t(sumArray, arr, size);
t.join();
In this context:
- The
sumArrayfunction describes logic: what needs to be done and how to do it. This aspect focuses more on design. - However, it does NOT describe the physical execution: it does not specify who performs the task. Ultimately, the task must be dispatched to a physical entity (e.g., hardware threads) to complete the work.
Hardware Threads
Corresponding to logical threads are hardware threads, which form the physical foundation for executing logical threads.
In chip design, a hardware thread typically refers to the hardware unit designed to execute an instruction sequence. A CPU may have multiple cores, and each core might support hyper-threading, where two hyper-threads (or hardware threads) share certain physical resources within a single core.
From a software perspective, there's no need to distinguish between a real physical core and a virtual core (VCore) created through hyper-threading. For practical purposes, they can be treated as independent execution units, with each unit appearing as a logical CPU. From this perspective, a CPU is simply a collection of logical CPUs that software interacts with.
1.2 Relationship Between Threads, Cores, and Functions
The thread's entry function serves as the starting point of its execution. A thread begins execution from this entry function and processes one instruction at a time. During execution:
- The thread may call other functions.
- When a function is called, the control flow transfers to the called function, which continues execution.
- The called function can further call other functions, forming a function call chain.
In the array summation example, if the array is very large, even a simple loop-based summation may take significant time. To optimize performance, the array can be divided into smaller arrays or represented as a 2D array (an array of arrays). Each thread can handle the summation of one smaller array, and multiple threads can execute concurrently. The final results are then aggregated to produce the overall sum.
To improve processing speed, multiple threads can execute the same (or similar) computational logic on different segments of data. This allows the same logic to have multiple execution instances (threads), which corresponds to data-splitting threads. Alternatively, different threads can be assigned distinct entry functions, enabling them to execute different computational logic. This corresponds to logic-splitting threads. Both approaches leverage multithreading to maximize efficiency and performance.
Let’s use an example to explain the relationship between threads, cores, and functions. Assume there are two types of tasks to complete: walking dogs and cleaning rooms.
- Walking a dog involves putting a leash on the dog and taking it for a walk around the neighborhood. This describes the logic of dog walking, which corresponds to a function definition. It is a static concept tied to design.
- Each task ultimately requires a person to perform it. In this analogy, the person corresponds to the hardware (CPU/Core/VCore), which provides the physical foundation for completing tasks.
What corresponds to Logical threads? Task splitting.
Example:
Assume there are two tasks to complete: walking dogs and cleaning rooms. Now imagine there are 2 dogs to walk and 3 rooms to clean. The work can be divided as follows:
- Walking dogs is split into 2 tasks: one task for walking the small dog and another for walking the large dog.
- Cleaning rooms is split into 3 tasks: one for each room.
This results in 5 tasks in total (2 + 3). If there are only 2 people, these 2 people cannot complete all 5 tasks simultaneously. The scheduling system decides who does what at a given time.
For example:
- If Tom is walking the small dog, this corresponds to a thread being executed.
- If Jerry is cleaning room A, this corresponds to another thread in execution.
Threads are a dynamic concept. Tasks that are not currently being worked on are waiting to be executed. In the example, the large dog's task might be waiting due to insufficient people. Other reasons for threads being paused include interruptions, preemptions, or dependencies.
For instance, If Jerry receives an urgent phone call while cleaning, the cleaning task is temporarily suspended. Once Jerry finishes the call, he resumes cleaning, and the thread continues its execution.
If there is only 1 person, the 5 tasks can still be completed, either sequentially or interleaved. Similarly, in a single CPU/single core system, multithreaded programs can still run. The operating system uses time-slicing to manage far more tasks than the available CPUs or cores. While maximizing the use of multi-CPU/multi-core systems is an important goal of multithreaded program design, multithreading itself does not strictly require multiple CPUs or cores.
Some tasks can also be assigned to specific people, corresponding to CPU affinity or core binding in computing.
1.3 Program, Process, Thread, and Coroutine
Processes and threads are two essential concepts in operating systems, with both differences and connections between them.
1.3.1 Executable Program
A C/C++ source file, after being processed by a compiler (compilation + linking), generates an executable program file. These files differ in format across systems, such as the ELF format on Linux or the EXE format on Windows. An executable program file is a static concept.
1.3.2 What is a Process?
An executable program running on an operating system corresponds to a process, which is a dynamic concept. A process is a program in execution. Running the same executable file multiple times creates multiple processes, similar to how a class can create multiple instances.
IMPORTANT
Processes are the basic unit of resource allocation.
1.3.3 What is a Thread?
Threads within a process represent multiple execution flows, each executing independently in a concurrent manner. In operating systems,
CAUTION
the smallest unit of scheduling and execution is a thread, not a process.
Processes share resources such as memory and file descriptors. Threads within the same process share:
- Address space, including code (functions), global variables, heap, and stack.
- File descriptors, allowing them to access the same open files.
This shared context makes threads efficient for concurrent operations within a process.
1.3.4 Relationship Between Processes and Threads
Linus Torvalds offered profound insights into the relationship between processes and threads in a 1996 email. He argued:
- Differentiating processes and threads as separate entities is a legacy burden and an unnecessary distinction.
- Both processes and threads are essentially contexts of execution (COE), sharing these states:
- CPU state, including registers.
- MMU state, such as page mappings.
- Permission state, like user ID (uid) and group ID (gid).
- Communication state, such as open files and signal handlers.
Traditional thinking suggests threads maintain minimal states (e.g., CPU state), inheriting other contexts from processes. Linus dismissed this distinction, calling it a self-imposed limitation. In the Linux kernel:
- Processes and threads are implemented as tasks (task_struct), with threads considered lightweight processes (LWP).
- Threads and processes share equal footing, as evidenced by the
/procfile system. - A multithreaded application designates its original process as the main thread, forming a thread group.
Linus advocated for designing operating systems around COEs rather than separate process/thread concepts. Limited interfaces can then expose this functionality to meet user-space requirements, such as those defined by the pthreads library.
1.3.5 Coroutines
Coroutines are user-space constructs enabling multiple execution flows with lower context-switching overhead compared to threads. By redesigning backend systems with coroutines, platforms like WeChat achieved greater throughput and stability.
Coroutines have also been standardized in C++20, making them increasingly accessible for modern development.
1.4 Why Multithreading is Needed
1.4.1 What is Multithreading?
Multithreading refers to a scenario where multiple threads execute concurrently within a single process. Each thread represents an independent execution flow. Multithreading is a programming model that is independent of the processor and related to design choices.
Reasons for Multithreading
- Parallel Computing: Fully utilizes multiple cores, improving overall throughput and speeding up execution.
- Background Task Processing: Separates background threads from the main thread. This is indispensable in scenarios like responsive user interfaces or real-time systems.
1.4.2 Enhancing Processing Power Through Multithreading
Let’s consider an example: Suppose you are tasked with writing a program to count the occurrences of words in a set of text files. The program takes a list of file names as input and outputs a mapping of each word to its frequency.
// Type alias: Mapping of words to their counts
using word2count = std::map<std::string, unsigned int>;
// Merges a list of "word-to-count" mappings
word2count merge(const std::vector<word2count>& w2c_list) {
// Implementation to combine all maps (todo)
}
// Counts the occurrences of words in a single file
word2count word_count_a_file(const std::string& file) {
// Implementation to count words in a file (todo)
}
// Counts word frequencies across multiple files
word2count word_count_files(const std::vector<std::string>& files) {
std::vector<word2count> w2c_list;
for (auto &file : files) {
w2c_list.push_back(word_count_a_file(file));
}
return merge(w2c_list);
}
int main(int argc, char* argv[]) {
std::vector<std::string> files;
for (int i = 1; i < argc; ++i) {
files.push_back(argv[i]);
}
auto w2c = word_count_files(files);
return 0;
}
The above program is a single-threaded implementation. The word_count_files function is called by the main function and executes in the main thread.
If there are only a few or small files to process, the program will quickly return the results. However, if the number of files or their sizes is large, the program may take a long time to complete.
Revisiting the program reveals that word_count_a_file accepts a file as input, produces local results (word counts) specific to the file, and does not depend on external data or logic, making it ideal for concurrent execution. To optimize the program, a separate thread can be assigned to process each file using word_count_a_file. Once all threads complete execution, their results can be merged to generate the final output.
Starting a thread for each file might not always be appropriate. If there are tens of thousands of small files, creating tens of thousands of threads would result in significant overhead. Each thread would run for a very short time, and a considerable amount of time would be spent on thread creation and destruction. A better design involves using a thread pool.
- Set the thread pool size to the number of CPU cores or double the core count.
- Each worker thread attempts to retrieve a file from the shared file list (protected by locks for thread safety).
- If successful, the thread processes the file and computes the word count.
- If no files remain, the thread exits.
- After all worker threads have exited, the main thread merges the results.
This multithreaded program can significantly improve processing speed. The array summation problem mentioned earlier can adopt a similar approach. If the program runs on a multi-CPU, multi-core machine, it can fully utilize the hardware's capabilities. Accelerating execution through multithreading is one of the primary and most apparent benefits of this approach.
1.4.3 Changing Program Design with Multithreading
Another significant advantage of multithreading is improving program design in scenarios involving blocking calls. Without multithreading, such situations can make the code challenging to implement effectively.
For instance, consider a program that performs intensive computations while simultaneously monitoring standard input (e.g., keyboard input). If the keyboard receives input, the program must read, parse, and execute the input. However, if the function used to get keyboard input is blocking, and no input is currently available, the program's other logic will not get a chance to execute.
// Receive input from the keyboard, interpret it, and construct a Command object to return
Command command = getCommandFromStdInput();
// Execute the command
command.run();
In such situations, we typically create a separate thread to handle input reception while using another thread to process other computational logic. This approach prevents input handling from blocking the execution of other logic. This is another key advantage of multithreading, enabling responsiveness and efficiency in concurrent systems.
1.5 Thread-Related Concepts
1.5.1 Time Slicing
Time slicing is a strategy where the CPU divides its time into small slices and allocates these slices to different threads for execution. For example, the CPU might execute Thread A for a short period, then switch to Thread B, and then back to Thread A. This simplified scheduling mechanism allows multiple threads to share the CPU. In reality, time slicing is a highly simplified version of scheduling strategies. Modern operating systems use far more sophisticated scheduling techniques. If one second is divided into many small time slices, such as 100 slices of 10 milliseconds each, these slices are short enough that users perceive no delay. This creates the illusion that the computer is dedicated to the user's task, even though the CPU is shared. This effect is achieved through process abstraction, which makes each process seem like it exclusively occupies the CPU.
1.5.2 Context Switching
Context switching occurs when the operating system moves the currently running task off the CPU and selects a new task to execute. This process involves saving the state of the current thread and restoring the state of the next thread. Context switching is part of the task scheduling process and consumes CPU time (referred to as system time).
1.5.3 Thread-Safe Functions and Reentrancy
A process can have multiple threads running simultaneously, and these threads might execute the same function concurrently. If the results of concurrent execution in a multithreaded environment are the same as those in a single-threaded sequential execution, the function is considered thread-safe. Otherwise, it is not thread-safe.
Functions that do not access shared data are inherently thread-safe. Shared data includes global variables, static local variables, and class member variables. A thread-safe function operates only on its parameters and has no side effects. Such functions can be reentered safely by multiple threads.
Each thread has its own stack, and function parameters are stored in registers or on the stack. Local variables are also stored on the stack. Therefore, functions that operate solely on parameters and local variables do not experience data races when called concurrently by multiple threads.
The C standard library contains many interfaces that are not thread-safe. For example, time manipulation and conversion functions like ctime(), gmtime(), and localtime() use shared static data, making them unsuitable for concurrent use. To address this, the C standard provides thread-safe versions of these functions with _r suffixes, such as:
char* ctime_r(const time* clock, char* buf);
The thread-safe versions of these interfaces typically require an additional char *buf parameter. This allows the function to operate on the provided buffer rather than relying on static shared data. By avoiding the use of shared static data, these functions meet the requirements for thread safety.
1.5.4 Thread-Specific Data
Thread-Specific Data (TSD) refers to data that is private to a specific thread but can be accessed across multiple functions within that thread. This allows each thread to maintain its own independent state while sharing the same codebase.
Purpose
In a multithreaded program, global and static variables are shared across all threads. However, some scenarios require data that is:
- Thread-private: Accessible only by the thread that owns it.
- Persistent within the thread's lifetime: Available across multiple function calls in the same thread.
TSD enables such functionality, ensuring that each thread has its own copy of the variable, independent of other threads.
Example in C++
#include <iostream>
#include <thread>
// Thread-local variable
thread_local int threadID;
void displayThreadID(int id) {
threadID = id; // Assign thread-specific value
std::cout << "Thread ID: " << threadID << std::endl;
}
int main() {
std::thread t1(displayThreadID, 1);
std::thread t2(displayThreadID, 2);
t1.join();
t2.join();
return 0;
}
1.5.5 Blocking and Non-Blocking
A thread corresponds to a single execution flow. Under normal circumstances, instructions are executed sequentially, and the computational logic progresses. However, if for some reason a thread cannot continue its execution, it is said to be blocked. This is akin to coming home from work, realizing you forgot your keys, and being stuck at the door, unable to enter, while time passes without progress.
Threads can become blocked for various reasons:
Lock Acquisition Failure:
When a thread attempts to acquire a lock and fails (e.g., due to a sleeping lock), it is suspended by the operating system. The thread yields the CPU, allowing the OS to schedule another runnable thread. The blocked thread is placed in a waiting queue and enters a sleep state.Blocking System Calls:
A thread may call a blocking system function and wait for an event to occur. Examples include: Reading data from a socket when no data is available or Fetching messages from an empty message queue.Busy Waiting:
A thread may continuously execute test-and-set instructions in a tight loop without success. Although the thread remains on the CPU, it wastes resources (busy waiting) and fails to progress its logic.
2. Multithreading Synchronization
Previously, we discussed the fundamentals of multithreading. Now, we move on to the second topic: multithreading synchronization.
2.1 What is Multithreading Synchronization?
In a single process, multiple threads share data. Concurrent access to shared data can result in a Race Condition.
Multithreading synchronization refers to:
- Coordinating access to shared data among multiple threads to avoid data inconsistencies.
- Managing the sequence of events across threads to ensure threads align at specific points and progress in the expected order. For example, one thread might need to wait for another thread to complete a task before proceeding to its next step.
To fully grasp multithreading synchronization, it is crucial to understand why synchronization is necessary and the situations where synchronization is required.
2.2 Why Synchronization is Necessary
Understanding why synchronization is needed is key to multithreaded programming. In fact, this is even more critical than learning the synchronization mechanisms themselves (how). Identifying areas that require synchronization is one of the most challenging aspects of writing multithreaded programs. Only by accurately recognizing the data that needs protection and the points where synchronization is required, and then applying appropriate mechanisms provided by the system or language, can safe and efficient multithreaded programs be written.
Below are examples illustrating why synchronization is necessary.
Example 1
Consider a character array msg of length 256, which is used to store messages. The functions read_msg() and write_msg() are used to read and write to msg, respectively:
// Example 1
char msg[256] = "this is old msg";
char* read_msg() {
return msg;
}
void write_msg(char new_msg[], size_t len) {
memcpy(msg, new_msg, std::min(len, sizeof(msg)));
}
void thread1() {
char new_msg[256] = "this is new msg, it's too looooooong";
write_msg(new_msg, sizeof(new_msg));
}
void thread2() {
printf("msg=%s\n", read_msg());
}
If thread1 calls write_msg() and thread2 calls read_msg() concurrently without protection, inconsistencies may occur. Since the msg array has a length of 256 bytes, writing the entire array requires multiple memory cycles. While thread1 writes a new message to msg, thread2 might read inconsistent data.
For example:
thread2could read the beginning of the new message, such as"this is new msg", while the latter part,"it's too...", has not yet been written bythread1.- This results in incomplete or inconsistent data being read by
thread2, as it does not reflect a coherent state of themsgarray.
In this case, the inconsistency manifests as incomplete data, where the read_msg() function retrieves a partial update, leading to unpredictable or erroneous behavior.
Example 2
Consider a binary search tree (BST) where each node is represented by a structure with three components:
- A pointer to the parent node.
- A pointer to the left subtree.
- A pointer to the right subtree.
Here’s the structure:
// Example 2
struct Node {
struct Node* parent;
struct Node* left_child;
struct Node* right_child;
};
These three components are interrelated. When adding a node to a BST, all three pointer fields—parent, left_child, and right_child—must be set. Similarly, when removing a node from the BST, the pointers in the parent node, left child, and right child must be updated.
Updating multiple pointer fields cannot be completed within a single instruction cycle. If one component is written while others remain unset, other threads may read the partially updated node. This can lead to inconsistencies, such as:
- Some pointer fields being updated while others are still invalid.
- Operations based on these partially updated pointers leading to errors, such as accessing incorrect or uninitialized memory.
Example 3
Consider two threads incrementing the same integer variable. The initial value of the variable is 0, and after both threads have completed their increments, the expected value of the variable is 2.
Here’s the code:
// Example 3
int x = 0; // Initial value is 0
void thread1() { ++x; }
void thread2() { ++x; }
The simple increment operation ++x consists of three steps:
- Load: Read the value of
xfrom memory into a register. - Update: Perform the increment operation in the register.
- Store: Write the updated value of
xback to memory.
When two threads execute ++x concurrently, the following scenarios may occur:
- If two threads execute the increment operation sequentially, such that the operations are temporally separated (e.g., Thread1 completes its increment before Thread2 begins, or vice versa), the final value of
xwill correctly be2, as expected. - If the operations are not fully separated in time, and Thread1 executes on core1 while Thread2 executes on core2, the following sequence of events might occur:
- Thread1 reads the value of
xinto core1's register. Simultaneously, Thread2 loads the value ofxinto core2's register. At this point, the copies ofxin both cores' registers are0. - Thread1 increments its local copy of
xin core1's register (0 -> 1). Concurrently, Thread2 increments its local copy ofxin core2's register (0 -> 1). - Thread1 writes its updated value (
1) back to the memory location ofx.Subsequently, Thread2 writes its updated value (1) to the same memory location ofx. The value ofxin memory is overwritten by Thread2's write operation. The final value ofxis1, which is incorrect and does not match the expected result of2.
- Thread1 reads the value of
Thread1 and Thread2 interleaving on the same core can also result in the same issue. This problem is independent of the hardware architecture. The main reason for the unexpected outcome is that the "load + update + store" sequence cannot be completed in a single memory cycle.
When multiple threads read and write to the same variable concurrently without synchronization, data inconsistency can occur.
In this example, the inconsistency is reflected in the final value of x, which may end up being either 1 or 2, depending on the specific interleaving of the operations performed by the two threads. Proper synchronization mechanisms are required to ensure consistency and correctness in such cases.
Example 4: Implementing a Queue Using a C++ Class Template
Below is an example of implementing a simple queue using a C++ class template
// Example 4: Simple Queue Implementation with Fixed Capacity
template <typename T>
class Queue {
static const unsigned int CAPACITY = 100;
T elements[CAPACITY];
int num = 0, head = 0, tail = -1;
public:
// Enqueue operation: Adds an element to the queue
bool push(const T& element) {
if (num == CAPACITY) return false;
tail = (++tail) % CAPACITY;
elements[tail] = element;
++num;
return true;
}
// Dequeue operation: Removes the front element from the queue
void pop() {
assert(!empty());
head = (++head) % CAPACITY;
--num;
}
// Check if the queue is empty
bool empty() const {
return num == 0;
}
// Access the front element of the queue
const T& front() const {
assert(!empty());
return elements[head];
}
};
Code Explanation
Data Storage:
T elements[]is used to store the data. Two cursors,headandtail, track the positions (indices) of the front and rear of the queue, respectively.push()Method:
First, thetailcursor is moved (incremented in a circular manner). Then, the element is added to the position indicated bytail.pop()Method:
Theheadcursor is moved to the next position (in a circular manner), logically removing the front element from the queue.front()Method:
Returns a reference to the element at the front of the queue.Assertions:
Bothfront()andpop()methods begin with an assertion to ensure the queue is not empty. Client code callingpop()orfront()must ensure the queue is non-empty before invoking these methods.
Assume we have an instance of Queue<int> named q. To avoid potential assertion failures when calling pop() directly, we can wrap it in a try_pop() method. The implementation is as follows:
Queue<int> q;
void try_pop() {
if (!q.empty()) { // Check if the queue is not empty
q.pop(); // Safely remove the front element
}
}
If multiple threads call try_pop() concurrently, problems can arise due to the nature of the operation.
Reason
The issue stems from the fact that the two operations—checking if the queue is empty and removing the front element—cannot be completed within a single instruction cycle. This creates a potential race condition.
Example 5
This example demonstrates a simple scenario of multithreaded read and write operations on an int32_t variable.
// Example 5
int32_t data[8] = {1, 2, 3, 4, 5, 6, 7, 8};
struct Foo {
int32_t get() const { return x; }
void set(int32_t x) { this->x = x; }
int32_t x;
} foo;
void thread_write1() {
for (;;) {
for (auto v : data) {
foo.set(v);
}
}
}
void thread_write2() {
for (;;) {
for (auto v : data) {
foo.set(v);
}
}
}
void thread_read() {
for (;;) {
printf("%d", foo.get());
}
}
Two writer threads and one reader thread are involved. The writer threads continuously loop through the data array, setting the x field of the foo object using the elements of the array. The reader thread simply prints the value of the x field from the foo object.
If the program runs indefinitely, will the printed data include values other than those initialized in the data array?
Is there an issue with the implementation of Foo::get? If so, what is the problem?
Example 6
This example demonstrates a simple FIFO queue implemented using a circular array. It includes methods for writing (put()) and reading (get()), where one thread writes data, and another thread reads data.
#include <iostream>
#include <algorithm>
// Circular FIFO queue using an array
class FIFO {
static const unsigned int CAPACITY = 1024; // Queue capacity (must be a power of 2)
unsigned char buffer[CAPACITY]; // Data storage buffer
unsigned int in = 0; // Write position
unsigned int out = 0; // Read position
// Calculate available free space in the buffer
unsigned int free_space() const {
return CAPACITY - (in - out);
}
public:
// Writes data to the buffer
// Returns the number of bytes actually written (<= len). If less than `len`, the buffer is full.
unsigned int put(unsigned char* src, unsigned int len) {
len = std::min(len, free_space()); // Determine the actual writable length
// Calculate free space from `in` to the end of the buffer
unsigned int l = std::min(len, CAPACITY - (in & (CAPACITY - 1)));
// Step 1: Copy data to the buffer starting at `in`, up to the buffer's end
memcpy(buffer + (in & (CAPACITY - 1)), src, l);
// Step 2: Copy remaining data to the beginning of the buffer if needed
memcpy(buffer, src + l, len - l);
in += len; // Update the write position, wrapping around on overflow
return len;
}
// Reads data from the buffer
// Returns the number of bytes actually read (<= len). If less than `len`, the buffer doesn't have enough data.
unsigned int get(unsigned char* dst, unsigned int len) {
len = std::min(len, in - out); // Determine the actual readable length
// Calculate available data from `out` to the end of the buffer
unsigned int l = std::min(len, CAPACITY - (out & (CAPACITY - 1)));
// Step 1: Copy data from the buffer starting at `out`, up to the buffer's end
memcpy(dst, buffer + (out & (CAPACITY - 1)), l);
// Step 2: Copy remaining data from the beginning of the buffer if needed
memcpy(dst + l, buffer, len - l);
out += len; // Update the read position, wrapping around on overflow
return len;
}
};
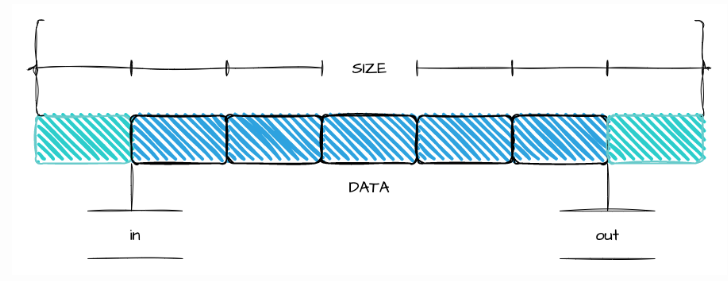 A circular queue is a logical concept. Since it uses an array as the underlying data structure, its actual physical storage is not circular.
A circular queue is a logical concept. Since it uses an array as the underlying data structure, its actual physical storage is not circular.put()Method:
Used to insert data into the queue. The parameterssrcandlendescribe the data to be inserted.get()Method:
Used to retrieve data from the queue. The parametersdstandlendescribe where to store the data and how many bytes to read.Capacity Selection:
The capacity is carefully chosen to be a power of 2, providing three main benefits:-. Cleverly leverages unsigned integer overflow to handle the movement of
inandout. -. Simplifies length calculation using bitwise AND (&) instead of modulus operations. -. For more details, search for "kfifo."inandoutCursors:in: Points to the position where new data will be written. Incrementinginis all that is needed after writing.out: Indicates the position in the buffer from which data will be read. Incrementingoutis all that is needed after reading.- The monotonic increase of
inandoutis enabled by the carefully chosen capacity.
Simplifications:
The queue's capacity is limited to 1024 bytes and does not support dynamic resizing, which simplifies the implementation without affecting discussions about multithreading.
When writing, data is written first, and then the in cursor is updated. When reading, data is copied first, and then the out cursor is updated. The consumer can only access newly inserted data via get() after the in cursor has been updated.
Intuitively, two threads performing concurrent reads and writes without synchronization might cause problems. But is there really an issue? If so, what is the issue, and how can it be resolved?
2.3 What to Protect
In a multi-threaded program, the focus is on protecting data, not the code itself. While some languages, like Java, provide constructs such as critical sections or synchronized methods, the ultimate goal is to ensure the safety and integrity of the data accessed by the code.
2.4 Serialization
Serialization occurs when one thread is accessing a shared (critical) resource, and no other threads are allowed to execute code that accesses the same resource (such code is called critical code) until the first thread finishes. Any other thread attempting to access the same resource must wait until the current thread completes its access.
This concept is commonly seen in real-life scenarios. For example, on a highway, cars passing through a checkpoint with a single lane must do so one at a time, even if the highway itself has multiple lanes. At the checkpoint, all cars funnel into the single lane in an orderly sequence.
Imposing this constraint on multi-threaded access to shared resources is called serialization.
2.5 Atomic Operations and Atomic Variables
For the earlier problem of two threads incrementing the same integer variable, the issue would be resolved if the three steps—load, update, and store—were an indivisible unit. In other words, if the increment operation ++x were atomic, the program would function correctly.
In this case, when two threads execute ++x concurrently, only two possible outcomes exist:
- Thread A executes
++x, followed by Thread B executing++x. The result is2. - Thread B executes
++x, followed by Thread A executing++x. The result is2.
No other outcomes are possible. The order in which Thread A and Thread B execute depends on thread scheduling but does not affect the final result.
Both the Linux operating system and the C/C++ programming language provide atomic integer variables. Increment, decrement, and other operations on these variables are atomic, meaning they are indivisible operations. For users of atomic variables, this guarantees:
- The operation is seen as a complete unit, with no intermediate states visible.
- From an observer's perspective, the variable is either unmodified or fully modified.
How atomicity is guaranteed is an implementation detail handled at lower levels. Application developers only need to understand atomicity conceptually and use it appropriately. Atomic variables are particularly well-suited for use cases such as counters and generating sequential identifiers.
2.6 Locks
Previously, we discussed several examples illustrating the problems caused by unsynchronized concurrent access to data in multi-threaded environments. Now, let's explore how to use locks to achieve synchronization.
2.6.1 Mutex Locks
For the issue of Thread 1 calling write_msg() and Thread 2 calling read_msg(), the problem can be avoided if Thread 2 is prevented from calling read_msg() while Thread 1 is executing write_msg(). This requirement ensures that multiple threads access shared resources mutually exclusively.
A mutex lock is a synchronization mechanism designed to meet this requirement. "Mutual exclusion" means only one thread can access the shared resource at a time.
States of a Mutex Lock
A mutex lock has exactly two states:
- Locked: Indicates that the lock is currently held by a thread.
- Unlocked: Indicates that the lock is available for acquisition.
A mutex lock has exactly two states:
- Locked: Indicates the mutex is currently held by a thread and cannot be acquired by another thread until released.
- Unlocked: Indicates the mutex is available and can be acquired by any thread.
A mutex lock provides two key interfaces:
Lock (Acquire):
- If the mutex is in the unlocked state, the thread successfully acquires the lock (sets the mutex to the locked state) and proceeds.
- If the mutex is in the locked state, any thread attempting to acquire it will be blocked until the mutex is released.
Unlock (Release):
- Sets the mutex to the unlocked state, releasing it.
- Any threads waiting for the lock will be given an opportunity to acquire it. If multiple threads are waiting, only one thread will successfully acquire the lock and continue execution.
To synchronize threads accessing a shared resource, we associate a mutex lock with the resource. Each thread must follow the three steps of locking, accessing, and unlocking when interacting with the resource:
DataType shared_resource;
Mutex shared_resource_mutex;
void shared_resource_visitor1() {
// Step 1: Lock the mutex
shared_resource_mutex.lock();
// Step 2: Operate on the shared resource
// operation1
// Step 3: Unlock the mutex
shared_resource_mutex.unlock();
}
void shared_resource_visitor2() {
// Step 1: Lock the mutex
shared_resource_mutex.lock();
// Step 2: Operate on the shared resource
// operation2
// Step 3: Unlock the mutex
shared_resource_mutex.unlock();
}
The functions shared_resource_visitor1() and shared_resource_visitor2() represent different operations on the shared resource. Multiple threads might call the same operation function or different operation functions.
Assume Thread 1 executes shared_resource_visitor1(). Before accessing the data, the function attempts to acquire a lock. If the mutex is already locked by another thread, the thread calling this function will block at the lock acquisition step until the other thread finishes accessing the data and releases (unlocks) the mutex. At that point, the blocked Thread 1 will be awakened and attempt to acquire the lock again.
If there are no other threads requesting the lock, Thread 1 will successfully acquire the lock, gain access to the resource, complete its operation, and then release the lock.
If other threads are also requesting the lock:
- If another thread acquires the lock, Thread 1 will remain blocked.
- If Thread 1 acquires the lock, it will access the resource, release the lock after completing its operation, and other threads competing for the lock will have the opportunity to continue execution.
If the cost of blocking due to a failed lock acquisition is unacceptable, the try_lock() interface of the mutex can be used. This method immediately returns if the lock acquisition fails, allowing the thread to avoid being blocked.
NOTE
Acquiring the lock before accessing the resource and releasing the lock after access is a programming contract. By adhering to this contract, data consistency is ensured. However, it is not an enforced restriction. If one thread follows the three-step process (lock, access, unlock) and another thread does not, the code will still compile and the program will run, but the results may be incorrect.
2.6.2 Read-Write Lock
A read-write lock functions similarly to a mutex in that threads are blocked when the lock cannot be acquired. However, it differs from a mutex in that it has three distinct states:
- Read-Locked State:
- Write-Locked State:
- Unlocked State:
Corresponding to its three states, a read-write lock provides three interfaces:
Acquire Read Lock:
- If the lock is in the write-locked state, the requesting thread is blocked.
- Otherwise, the lock is set to the read-locked state, and the operation succeeds.
Acquire Write Lock:
- If the lock is in the unlocked state, it is set to the write-locked state, and the operation succeeds.
- Otherwise, the requesting thread is blocked.
Unlock:
- The lock is set to the unlocked state and the operation returns.
A read-write lock enhances thread parallelism, thereby increasing throughput. It allows multiple read threads to access shared resources simultaneously, while write threads, when accessing shared resources, block all other threads from execution. As such, read-write locks are suitable for scenarios where read operations outweigh write operations.
Read-write locks are also known as shared-exclusive locks. Multiple read threads can access the same resource concurrently, representing the shared aspect of the lock. On the other hand, write threads are exclusive—when a write thread is accessing the resource, no other threads, whether reading or writing, are allowed to enter the critical section.
Consider a scenario where Threads 1, 2, and 3 share a resource x, protected by a read-write lock (rwlock):
Thread 1 starts a read operation on resource x. Since no write lock is held, Thread 1 acquires the read lock and begins reading. Thread 2 attempts to write to resource x. However, because the rwlock is currently held in a read-locked state by Thread 1, Thread 2 is blocked. After some time, Thread 3 also starts a read operation on resource x. Since reads are shared, Thread 3 can proceed concurrently with Thread 1. When Thread 1 finishes its read operation, Thread 3 continues accessing the resource. Meanwhile, Thread 2 remains blocked, as the write operation requires exclusive access. Before Thread 3 completes its read operation, Thread 1 again requests to read resource x. Because read operations are shared, Thread 1 is granted access immediately. Thread 2, however, remains blocked.
2.6.3 Spinlock
A spinlock has interfaces similar to a mutex but operates differently in principle. When a thread fails to acquire a spinlock, it does not voluntarily yield the CPU or enter a sleep state. Instead, it engages in busy-waiting, repeatedly executing a Test-And-Set (TAS) instruction until the TAS succeeds. During this process, the thread continuously occupies the CPU while attempting to acquire the lock.
Spinlocks are designed with specific usage scenarios in mind. They assume that once a thread successfully acquires the spinlock, it will release the lock very quickly. This means that:
- The critical section executed by the thread is very short.
- The logic for accessing the shared resource is simple.
Under these conditions, other threads attempting to acquire the spinlock will only need to busy-wait for a short time before acquiring the lock. This avoids being scheduled away into a sleep state. Spinlocks operate under the assumption that the cost of spinning is lower than the cost of thread scheduling, as scheduling involves saving and restoring thread context, which consumes CPU resources.
Kernel-mode threads can easily meet these conditions. In kernel-mode interrupt handling functions, scheduling can be disabled to prevent CPU preemption. Additionally, some kernel-mode threads invoke functions that cannot sleep, making spinlocks the only viable option for synchronization.
Optimized mutex implementations in Linux systems incorporate a hybrid approach. When acquiring a mutex, the thread first performs a limited number of spins. If the lock cannot be acquired within those spins, the thread enters sleep mode and yields the CPU. This design ensures that mutexes perform efficiently in most scenarios.
Additionally, spinlocks are only effective in systems with multiple CPUs or cores. On a single-core system, if a thread is busy-waiting on a spinlock, no other thread, including the one holding the lock, can execute. This prevents the lock from being released, rendering the spinlock ineffective.
2.6.4 Lock Granularity
It is important to set an appropriate level of lock granularity:
- Granularity too large: This reduces performance by limiting parallelism.
- Granularity too small: This increases code complexity and the difficulty of implementation.
2.6.5 Lock Scope
The scope of a lock should be as small as possible to minimize the time a lock is held. Keeping the locked section short improves performance and reduces contention among threads.
2.6.6 Deadlocks
Deadlocks occur in programs for two typical reasons:
1. ABBA Deadlock
Consider a scenario with two resources, X and Y, protected by locks A and B respectively:
Thread 1 acquires lock A to access resource X and then tries to acquire lock B to access resource Y. Meanwhile, Thread 2 acquires lock B to access resource Y and then tries to acquire lock A to access resource X. Both threads are now waiting for the other to release its lock:
- Thread 1 waits for lock
B, which is held by Thread 2. - Thread 2 waits for lock
A, which is held by Thread 1.
This results in a circular wait where neither thread can proceed, leading to a deadlock.
While the above case seems straightforward, in large programs, such deadlocks can be obscured by complex call hierarchies. At its core, this scenario describes an ABBA deadlock, where one thread holds lock A while requesting lock B, and another holds lock B while requesting lock A.
Solutions:
- Try Lock: Use a
try_lock()method to attempt acquiring the second lock. If the attempt fails, release the first lock and retry. - Lock Ordering: Enforce a consistent locking order (e.g., always acquire lock
Abefore lockB). This avoids circular waits.
2. Self-Deadlock
In systems that do not support reentrant locks (locks that allow the same thread to acquire them multiple times):
- A thread holding a lock attempts to acquire the same lock again.
- Since the lock is already held by the thread itself, the request cannot be satisfied, causing the thread to block indefinitely.
This scenario also results in a deadlock, known as a self-deadlock.
2.7 Condition Variables
Condition variables are commonly used in the producer-consumer pattern and must be paired with mutexes for proper synchronization.
Suppose you are developing a network processing program. The I/O thread receives a byte stream from a socket, deserializes it into individual messages using a custom protocol, and then places these messages into a message queue. A group of worker threads retrieves messages from the queue and processes them.
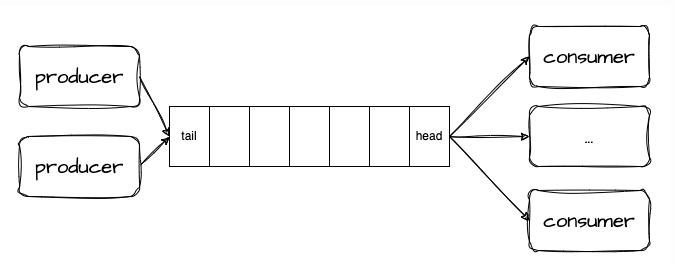 You can configure the queue with a mutex to ensure synchronization. Both the
You can configure the queue with a mutex to ensure synchronization. Both the put and get operations are preceded by a lock acquisition and followed by a lock release. The code could look like this:void io_thread() {
while (1) {
Msg* msg = read_msg_from_socket();
msg_queue_mutex.lock();
msg_queue.put(msg);
msg_queue_mutex.unlock();
}
}
void work_thread() {
while (1) {
msg_queue_mutex.lock();
Msg* msg = msg_queue.get();
msg_queue_mutex.unlock();
if (msg != nullptr) {
process(msg);
}
}
}
In the current implementation, each thread in the worker thread group continuously checks the message queue for messages. If a message is present, the thread retrieves it and processes it. If the queue is empty, the thread remains in a loop, repeatedly checking for new messages.
This busy-waiting approach results in significant CPU usage even under light workloads, as the work_thread continues consuming CPU cycles while repeatedly checking an empty queue. This inefficiency arises because threads are actively polling the queue instead of waiting for a condition that indicates new messages have arrived.
To reduce CPU usage in worker threads, we could introduce a short sleep interval between consecutive queue checks. However, determining the optimal sleep duration poses challenges:
- If the interval is too long, messages may experience delays before being processed, leading to increased latency.
- If the interval is too short, the CPU will still be consumed unnecessarily, as frequent polling wastes resources.
This method of repeatedly checking for a condition is called polling.
Polling is analogous to waiting for a package at your local post office. Instead of repeatedly going downstairs to check if the package has arrived, it would be far more efficient to wait for a notification from the mailroom when the package is ready for pickup.
Conditional variables provide a notification mechanism similar to notify, enabling two types of threads to synchronize at a specific point. A conditional variable allows a thread to wait for a certain condition to occur.
This condition is protected by a mutex, making it mandatory to pair conditional variables with mutexes for proper usage. The process works as follows:
- A thread must first acquire the mutex before modifying the condition.
- After modifying the condition state, the thread releases the mutex and sends a notification.
- Threads waiting for the condition enter a sleep state and release the mutex.
- When notified, a waiting thread wakes up, reacquires the mutex, and checks the condition state.
- If the condition is not satisfied, the thread goes back to sleep and releases the mutex again.
By coordinating threads through conditional variables, synchronization is achieved efficiently without relying on busy-waiting, reducing CPU resource consumption. In the above example, the condition that the worker threads wait for is the message queue being non-empty. The code can be rewritten using conditional variables as follows:
void io_thread() {
while (1) {
Msg* msg = read_msg_from_socket();
{
std::lock_guard<std::mutex> lock(msg_queue_mutex);
msg_queue.push_back(msg);
}
msg_queue_not_empty.notify_all();
}
}
void work_thread() {
while (1) {
Msg* msg = nullptr;
{
std::unique_lock<std::mutex> lock(msg_queue_mutex);
msg_queue_not_empty.wait(lock, [] { return !msg_queue.empty(); });
msg = msg_queue.get();
}
process(msg);
}
}
std::lock_guard: A simple RAII wrapper for a mutex. It locks the mutex when created and automatically unlocks it when destroyed.std::unique_lock: Similar tostd::lock_guard, but provides additional flexibility, such as the ability to manually unlock the mutex before the scope ends.wait:- It makes the current thread sleep until the condition variable is notified.
- It automatically unlocks the lock while waiting and reacquires it once woken up.
The wait() function makes the current thread sleep until the condition variable is notified. It automatically unlocks the lock while waiting and reacquires it once woken up.
When the producer thread delivers messages to msg_queue, it must lock the queue using a mutex. Notifications to the worker threads (notify_all) can be placed after unlocking the mutex for better performance.
- Protection with Mutex: The
msg_queue_not_emptycondition variable must be paired with themsg_queue_mutexto ensure safe and synchronized access to the queue. - Using
waitSafely:- The second parameter of
waitis a lambda expression that acts as a predicate. It evaluates whether the condition (e.g.,!msg_queue.empty()) is satisfied. - Multiple worker threads might be woken up simultaneously. Upon waking, each thread will reacquire the mutex and reevaluate the condition.
- If the condition is not satisfied, the thread will return to sleep.
- The second parameter of
2.8 Lock-Free and Non-Blocking Data Structures
2.8.1 Issues with Lock-Based Synchronization
Thread synchronization can be categorized into blocking and non-blocking synchronization.
Blocking Synchronization
Mechanisms like mutexes, semaphores, and conditional variables provided by the system fall under blocking synchronization. When threads compete for a shared resource, blocking synchronization may cause threads to be put into a blocked state, halting their execution until the resource is available.
Non-Blocking Synchronization
Non-blocking synchronization achieves synchronization without using locks. Instead, it relies on algorithms and technical methods that avoid thread blocking.
Locks are a form of blocking synchronization and come with inherent drawbacks:
- Program Stalling: If a thread holding a lock crashes or becomes unresponsive, the lock is never released, leaving other threads in an infinite wait state.
- Priority Inversion: A lower-priority thread holding a lock can block higher-priority threads, leading to inefficiencies and priority inversion issues.
To address these challenges, lock-free synchronization provides a non-blocking alternative.
2.8.2 What is Lock-Free?
Lock-free programming eliminates the problems associated with lock-based synchronization. All threads execute atomic instructions without waiting, instead of being blocked. For instance, one thread reading an atomic variable and another thread writing to it can operate without any waiting. Hardware-level atomic instructions ensure that:
- Data inconsistencies do not occur.
- Write operations are not partially completed.
- Read operations do not retrieve incomplete data
Let’s first look at Wikipedia’s description of lock-free:
Lock-freedom allows individual threads to starve but guarantees system-wide throughput. An algorithm is lock-free if, when the program threads are run for a sufficiently long time, at least one of the threads makes progress (for some sensible definition of progress). All wait-free algorithms are lock-free. In particular, if one thread is suspended, then a lock-free algorithm guarantees that the remaining threads can still make progress. Hence, if two threads can contend for the same mutex lock or spinlock, then the algorithm is not lock-free. (If we suspend one thread that holds the lock, then the second thread will block.)
CAUTION
If two threads compete for the same mutex or spinlock, it is not lock-free; this is because if the thread holding the lock hangs, the other thread will be blocked.
NOTE
To elaborate further: lock-free describes a property of the code logic, and most code that does not use locks possesses this property. People often confuse the concepts of lock-free and lock-less programming. In reality:
- Lock-free refers to a property of the code or algorithm, indicating its inherent characteristic.
- Lock-less refers to the implementation of the code, describing the method used.
In short, lock-free is about the nature of the code, while lock-less is about how the code is constructed.
Here’s an example from the opposite perspective. Suppose we aim to implement a "lock-free" queue using locks. We can directly use a thread-unsafe std::queue along with std::mutex as follows:
template <typename T>
class Queue {
public:
void push(const T& t) {
q_mutex.lock();
q.push(t);
q_mutex.unlock();
}
private:
std::queue<T> q;
std::mutex q_mutex;
};
If threads A, B, and C simultaneously call the push method, the first thread to enter, A, acquires the mutex. Threads B and C, unable to obtain the mutex, are put into a waiting state. If thread A is permanently suspended for any reason (e.g., an exception or waiting for some resource), threads B and C, which are also attempting to execute push, will be indefinitely blocked. This means the entire system is unable to make progress (system-wide progress halts), which clearly violates the requirements of lock-free behavior.
IMPORTANT
Thus, any concurrency implementation that relies on locks (including spinlocks) cannot be considered lock-free.
This is because they all face the same issue: if the thread or process currently holding the lock is permanently paused, it will block the execution of other threads or processes. In contrast, the definition of lock-free allows for the possibility of individual processes (or execution flows) starving but guarantees that the overall logic continues to make progress. Lock-based concurrency clearly violates the requirements of lock-free behavior.
2.8.3 CAS Loop to Achieve Lock-Free
Lock-free synchronization primarily relies on read-modify-write primitives provided by the CPU. One of the most well-known is Compare-And-Swap (CAS), which is implemented as atomic operations through the cmpxchg series of instructions on x86 architectures. The logic of CAS can be expressed in code as follows:
bool CAS(T* ptr, T expect_value, T new_value) {
if (*ptr != expect_value) {
return false;
}
*ptr = new_value;
return true;
}
Logical Description of CAS: CAS compares the value at a memory address with the expected value. If the values differ, the operation returns a failure. If they match, the new value is written to memory, and the operation returns success.
The C function described earlier only illustrates the logic of CAS. However, the operation itself is not atomic in this form, as it consists of multiple steps:
- Reading the value from memory.
- Comparing the value.
- Writing the new value.
Between these steps, other operations could potentially intervene. In practice, atomic instructions ensure that these steps are "packaged" together and executed as a single, uninterruptible unit. For instance, on x86 architectures, this behavior is often implemented using the lock; cmpxchg instruction. While the underlying implementation details are useful for understanding, programmers should primarily focus on understanding CAS behavior logically rather than worrying about the specific hardware-level implementation.
Lock-free code typically uses CAS (Compare-And-Swap) in conjunction with a loop to repeatedly attempt updates until successful. The pattern can be implemented as follows:
do {
T expect_value = *ptr;
} while (!CAS(ptr, expect_value, new_value));
NOTE
Step Three: While CAS itself is atomic, the process of loading expect_value and then performing the CAS operation are not atomic. This is why a loop is necessary. If the value at the memory address ptr remains unchanged (*ptr == expect_value), the new value is stored, and the operation returns success. However, if the value at ptr has been modified by another thread after loading expect_value, the CAS operation will fail. In this case, the loop retries by reloading expect_value and attempting the operation again. This retry process continues until the operation succeeds.
The ability of CAS loops to support concurrent writes from multiple threads is incredibly useful. In many multi-threaded synchronization scenarios, handling multiple writers is a common challenge.
Using CAS, we can implement the Fetch-and-Add (FAA) algorithm, which works as follows:
T faa(T& t) {
T temp = t; // Read the current value
while (!compare_and_swap(t, temp, temp + 1)); // Attempt to increment atomically
}
2.8.4 Lock-Free Data Structures: Lock-Free Stack
Lock-free data structures manage shared data using non-blocking algorithms instead of relying on locks. Non-blocking algorithms ensure that threads competing for shared resources are not indefinitely paused due to mutual exclusion.
By definition, non-blocking algorithms are lock-free because they guarantee system-wide progress regardless of thread scheduling. This means that even if some threads are delayed or interrupted, the system as a whole will continue to make progress.
Lock-free stacks are an excellent example of such data structures, where the use of atomic operations like CAS enables safe and efficient concurrent access without the need for traditional locking mechanisms.